April 2, 2026
Idempotency in Event-Driven Systems (Spring Boot + Kafka Demo)
Idempotency in Event-Driven Systems (Spring Boot + Kafka Demo)
In the previous article, we saw how the Outbox Pattern helps us reliably publish events with no event loss.
But even after reliable publishing, one problem still remains.
The same event can be delivered more than once.
This can happen because of:
- producer retries or resend after uncertain acknowledgement
- duplicate event publishing from application retry logic
- outbox message replay
- consumer retries
- consumer restart
- failure before offset commit
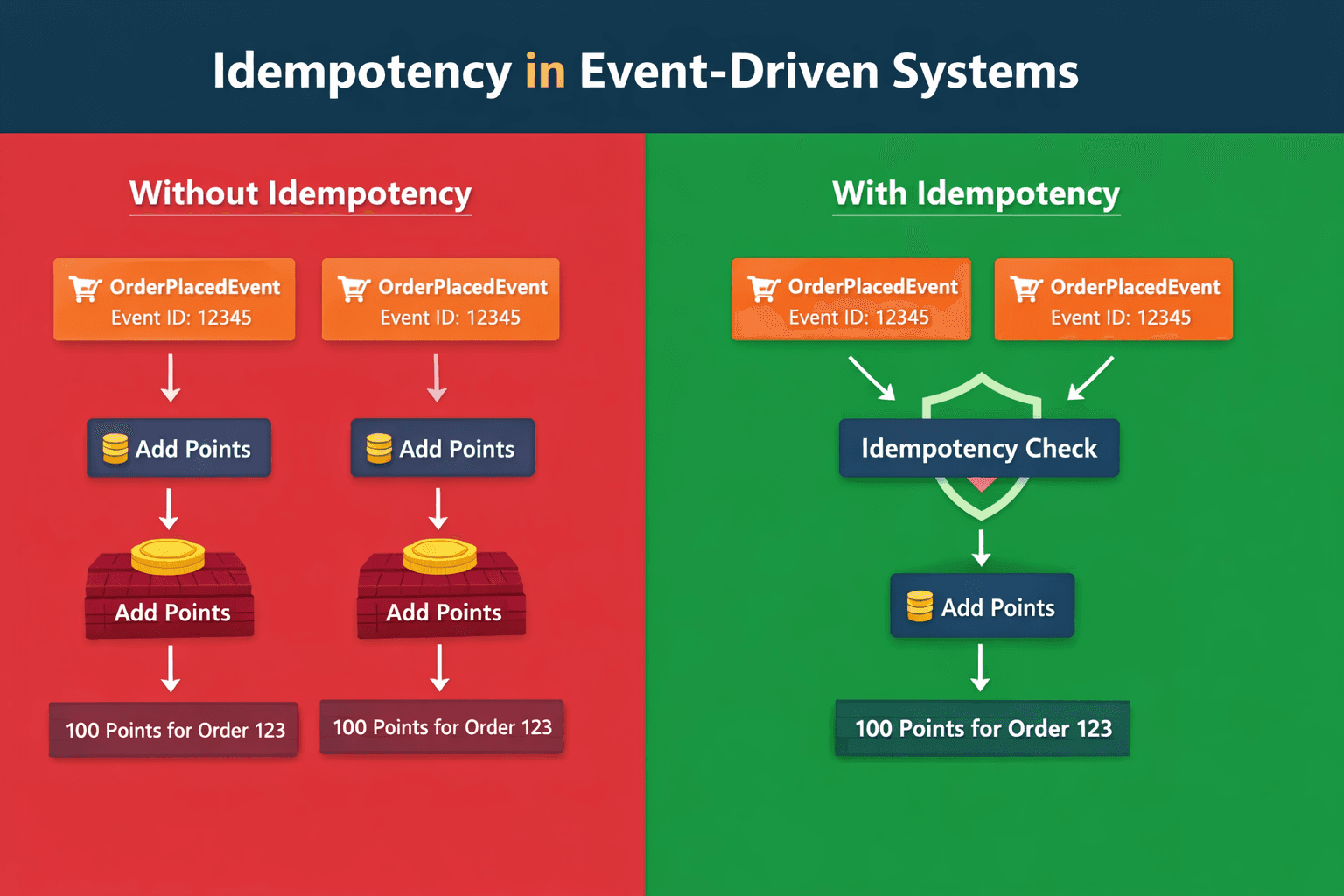
If our consumer is not designed carefully, the same business action may happen multiple times.
In this article, we will understand how to solve this problem using idempotent consumers, and we will build a simple implementation using Spring Boot + Kafka.
The Problem
Imagine a customer places an order worth ₹250.
Our LoyaltyPointsService consumes the OrderPlacedEvent and adds 25 reward points.
Now suppose Kafka redelivers the same event 3 times.
Without proper duplicate handling:
- first delivery → 25 points
- second delivery → 25 more points
- third delivery → 25 more points
Now the customer gets 75 points instead of 25.
This is a very common problem in event-driven systems.
This is where idempotency helps us.
Business Flow
This demo uses a simple loyalty points example.
- Customer places an order
OrderPlacedEventis published to KafkaLoyaltyPointsConsumerreads the event- reward points are added to the ledger
flowchart LR
A[Order Service] --> B[Kafka]
B --> C[Loyalty Consumer]
C --> D[Reward Ledger]Naive Consumer Implementation
Let us first see the wrong implementation.
In the naive version, whenever the consumer receives an event, it directly inserts a row into the reward ledger.
@Transactional
public void processWithoutIdempotency(OrderPlacedEvent event) {
rewardLedgerEntryRepository.save(new RewardLedgerEntry(
event.eventId(),
event.orderId(),
event.customerId(),
event.rewardPoints(),
Instant.now()));
log.info("Processed order {} without idempotency. Added {} points for customer {}.",
event.orderId(), event.rewardPoints(), event.customerId());
}
This means:
- every delivery is treated as a new event
- no duplicate check happens
- reward points are added repeatedly
At first, this implementation may look correct.
But the issue appears when the same event is delivered multiple times.
The Bug
To simulate duplicate delivery, we use this API:
POST /api/orders/duplicate?deliveries=3
We send the same event with the same eventId three times.
POST 'http://localhost:8081/api/orders/duplicate?deliveries=3' \
--header 'Content-Type: application/json' \
--body '{
"eventId":"evt-order-1001",
"orderId":"order-1001",
"customerId":"customer-37",
"orderTotal":250.00,
"rewardPoints":25
}'
Now if we check the reward ledger:

We can clearly see that the same customer received points three times for the same order.
This is the exact bug we want to solve.
The Solution: processed_events Table
To solve this, we create a table called processed_events.
This table stores every eventId that has already been processed.
A simple structure:
| Column | Purpose |
|---|---|
| event_id | unique event identifier |
| processed_at | when the event was handled |
Now before processing an incoming event:
- check whether
eventIdalready exists - if yes → skip processing
- if no → process normally
- save the
eventId
This makes the consumer idempotent.

Idempotent Consumer Implementation
Now let us see the correct implementation.
@Transactional
public void processWithIdempotency(OrderPlacedEvent event) {
if (processedEventRepository.existsByEventId(event.eventId())) {
log.info("Skipping duplicate event {} because it already exists in processed_events.",
event.eventId());
return;
}
rewardLedgerEntryRepository.save(new RewardLedgerEntry(
event.eventId(),
event.orderId(),
event.customerId(),
event.rewardPoints(),
Instant.now()));
processedEventRepository.saveAndFlush(
new ProcessedEvent(event.eventId(), "loyalty-points-service", Instant.now()));
log.info("Processed order {} with idempotency. Added {} points for customer {}.",
event.orderId(), event.rewardPoints(), event.customerId());
}
The flow is simple:
- first check
processed_events - if already processed → skip
- otherwise:
- add reward points
- save
eventId
This ensures the same event affects the business only once.
Why @Transactional Is Important
One very important thing here is:
- reward points insertion
- processed event insertion
Both should happen in the same transaction.
That is why we use @Transactional.
Why?
If reward points are saved but processed_events is not saved,
then the same event may be processed again.
If processed_events is saved but reward points fail,
then the event may be skipped even though business logic never completed.
So both operations should either:
- succeed together
- or rollback together
This is a very important production concept.
Switching Between Naive and Idempotent Mode
In this demo, both implementations are present in the same service:
processWithoutIdempotency()processWithIdempotency()
Which one gets used is controlled by a boolean flag in application.properties:
app.loyalty.idempotency-enabled=false
falseenables the naive versiontrueenables the idempotent version
This makes the demo easy to explain because we can run the exact same API request in both modes and compare the database result.
Running the Same Duplicate Scenario Again
Now enable idempotency mode.
app.loyalty.idempotency-enabled=true
Run the same API again:
POST /api/orders/duplicate?deliveries=3
Now check reward ledger - Only single row, as other 2 requests are skipped.
Check processed events

Now we can clearly see:
- first event was processed
- duplicate deliveries were ignored
flowchart LR
A[Order Service] -->|OrderPlacedEvent| B[Kafka Topic]
B --> C[Loyalty Consumer]
C --> D{Event Already Processed?}
D -- Yes --> E[Skip Processing]
D -- No --> F[Add Reward Points]
F --> G[Save to Reward Ledger]
G --> H[Store EventId in Processed Events]Before vs After
| Scenario | Reward Rows |
|---|---|
| Without idempotency | 3 |
| With idempotency | 1 |
This simple comparison clearly shows why consumer-side idempotency is required.
Outbox vs Idempotent Consumer
These two solve different problems.
Outbox Pattern
- ensures events are not lost
- solves reliable publishing
Idempotent Consumer
- ensures duplicate events do not break business logic
- solves safe consumption
Together, these patterns make event-driven systems much more reliable.
Conclusion
reliable publishing and safe processing are two different concerns.
Even if the producer publishes events reliably, the consumer should still be prepared for duplicate delivery.
A simple processed_events table is one of the easiest and most practical ways to solve this.
If you want to explore the full working demo, the source code is available here: backend-patterns-and-practices/idempotency-pattern.